Self Attention initially all you need
Self Attention initially all you need
Understanding the Key to Modern NLP Models and Transformers

When we start learning transformers, we must start with attention first, especially self-attention if you are a beginner in this field. It is one of the core concepts of transformer architecture.
1. Why do we need self-attention?
The main work of self-attention is to convert static embeddings of a sentence into a contextual embedding so that each word (token) may contain the context of the whole sentence, and we can get better and more efficient results.
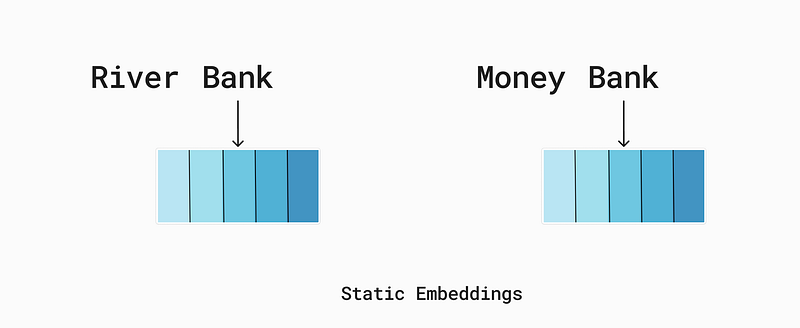
Now, here you may wonder why we need it, so to simplify, I am taking an example of two sentences where each sentence contains three words only:
- River Bank Short
- Money Bank Open
 Static Embeddings
Static Embeddings
In these two sentences, we have a common word, “Bank,” but it has a different meaning in both sentences. In sentence one, the bank refers to the “ground at the edge of the river,” whereas in sentence two, it refers to the “place where you can deposit money or transfer it to others.” If we use the same embedding for both sentences, the quality of our language model will be downgraded.
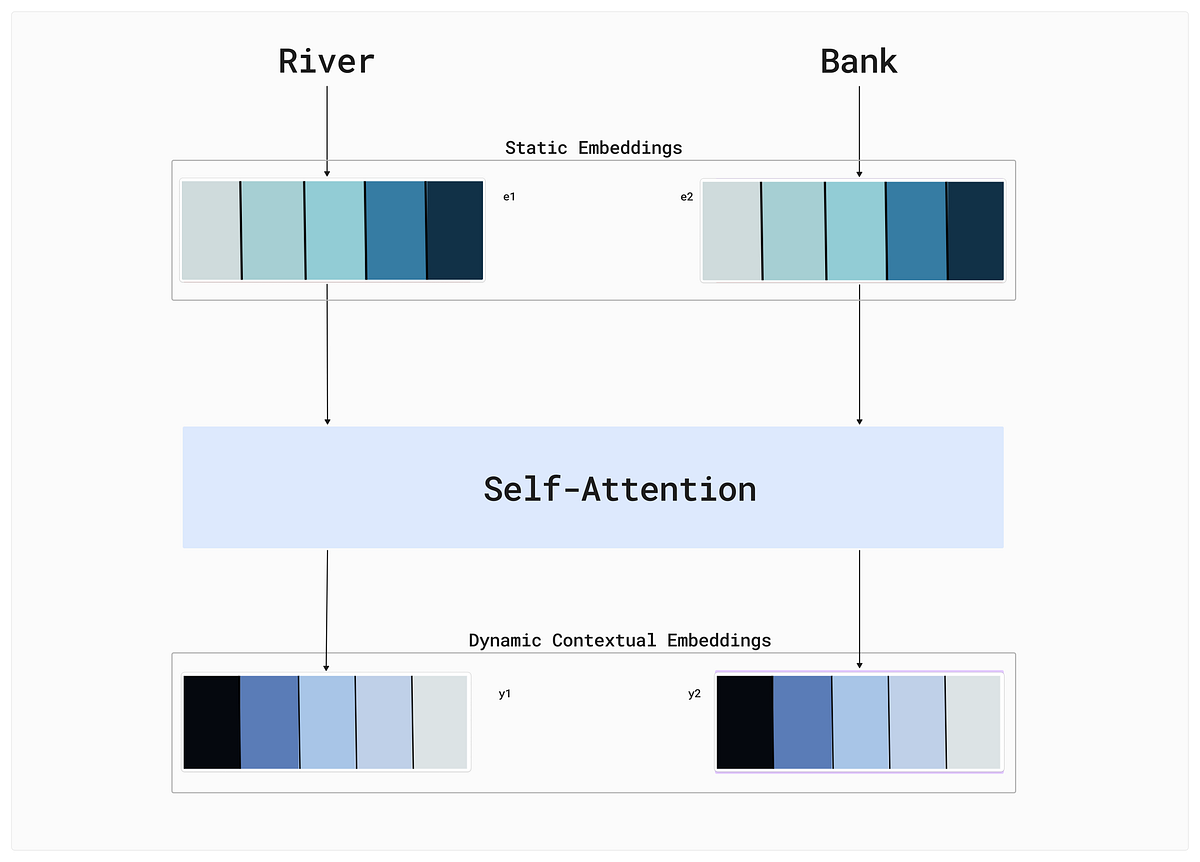
So, to solve this problem, we need to use contextual embeddings, which means embeddings must be dynamic. To solve this problem, self-attention is used, which helps us convert static embeddings to contextual embeddings.
 Self-Attention Overview
Self-Attention Overview
2. Let’s Understand how Self-Attention works
To understand it, we are going to take the first principle approach, but if you want to know the advanced part only, you can refer to the main paper, too Attention all you need. Now, Let’s start —
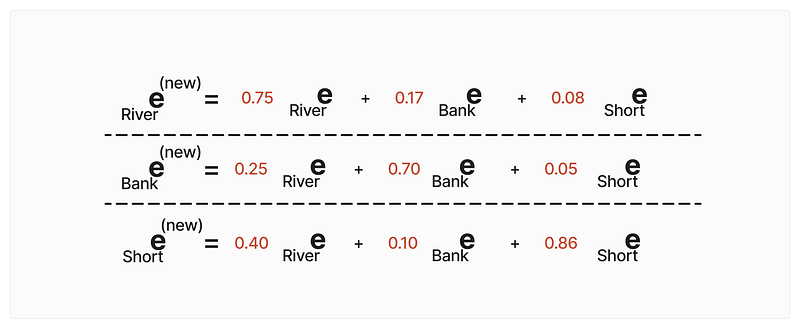
As we know, we have two sentences that we used above, and by using the static embeddings, the embeddings of the word “Bank” remain the same, which will lead to poor outputs. So, to overcome this, we think this way that the embedding of each word of the sentence is made up of by adding the particular percentage of each embedding of that sentence, which means instead of relying on only a single word for embedding, we are relying on the context (similarity) of each word of that sentence. For Instance — for the sentence “River Bank Short,” our new embeddings look like this.
River = 0.75 * River embeddings + 0.17 * Bank embedding + 0.08 * Short embedding
Bank = 0.25 * River embeddings + 0.70 * Bank embedding + 0.05 * Short embeddings
Short = 0.40 * River Embedding + 0.10 * Bank embedding + 0.86 * Short embeddings
From this, we can say our new embeddings of the sentence are made up of the sum of __(similarity value) time static embeddings of other words of that sentence.
 New Embeddings From Old Static embeddings
New Embeddings From Old Static embeddings
2.1 How can we calculate these contextual numbers?
So, if we take a look at these numbers, which we say are our contextual numbers, they are nothing but numbers that represent the similarity between the word for which we are calculating the embedding and the word with respect to which we are calculating it. Since we also know these embeddings are just n-dimensional vectors. So, to calculate the similarity, we can use the dot product of two vectors.
 Dot Product of Embedding (Values that we are using are just random values)
Dot Product of Embedding (Values that we are using are just random values)

 Complete Self-Attention Calculation
Complete Self-Attention Calculation
2.2 Python code for the above calculation:
import numpy as np
# Static embeddings
river = np.array([0.39, 0.10, 0.65, 0.79, 0.21])
bank = np.array([0.62, 0.25, 0.15, 0.87, 0.37])
short = np.array([0.49, 0.70, 0.05, 0.29, 0.58])
# Calculate dot products
river_dot_river = np.dot(river, river)
river_dot_bank = np.dot(river, bank)
river_dot_short = np.dot(river, short)
bank_dot_river = np.dot(bank, river)
bank_dot_bank = np.dot(bank, bank)
bank_dot_short = np.dot(bank, short)
short_dot_river = np.dot(short, river)
short_dot_bank = np.dot(short, bank)
short_dot_short = np.dot(short, short)
# Calculate contextual embeddings
e_new_river = river_dot_river * river + river_dot_bank * bank + river_dot_short * short
e_new_bank = bank_dot_river * river + bank_dot_bank * bank + bank_dot_short * short
e_new_short = short_dot_river * river + short_dot_bank * bank + short_dot_short * short
e_new_river, e_new_bank, e_new_short
So, till now, we have learned what self-attention is, why we need it, and how it works. Before moving further, I am also adding the complete process architecture for the word “river,” which we have learned till now —
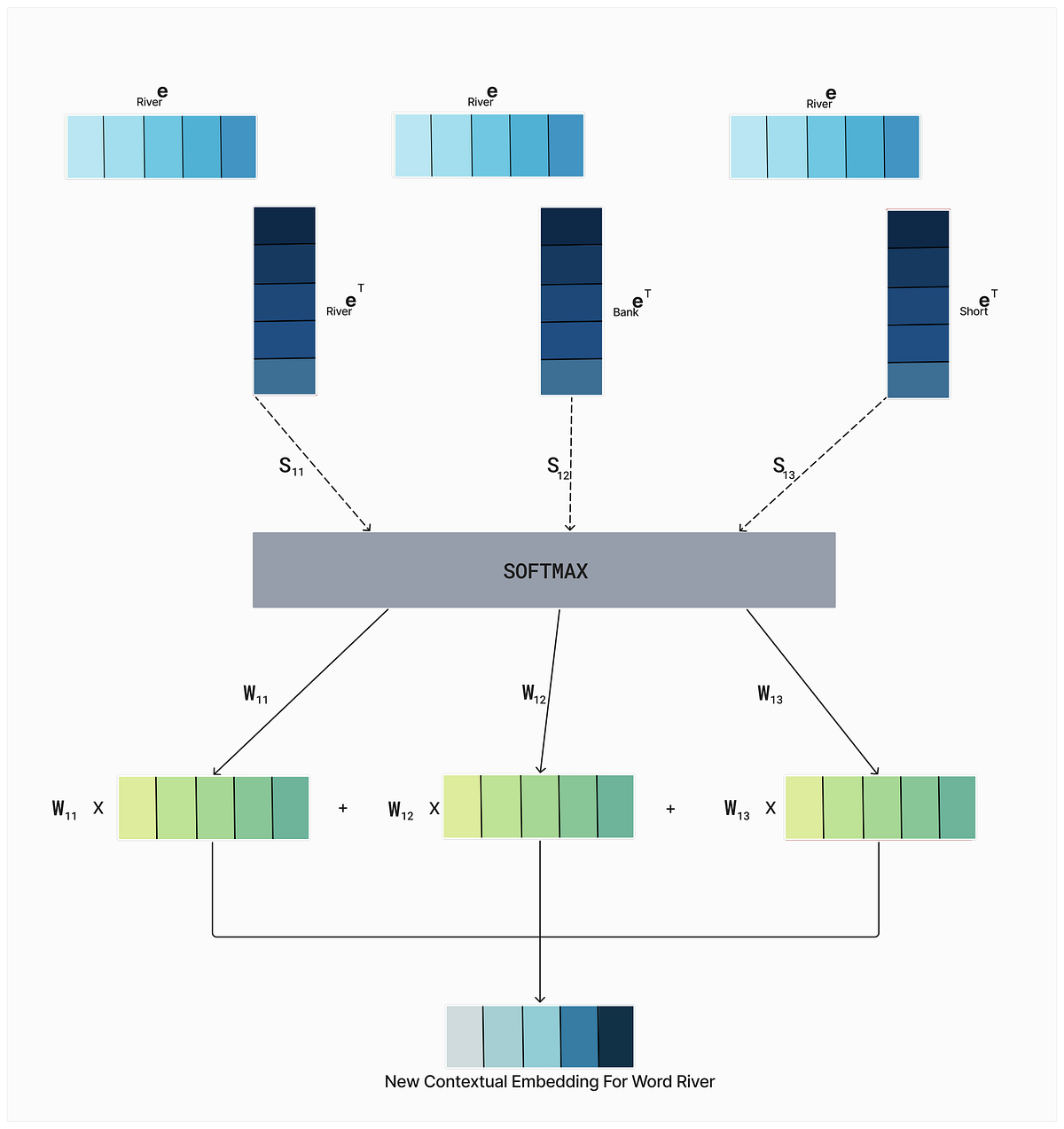
Here, we are using the “softmax layer“ to normalize the dot product values. We use it because sometimes we may get negative values.
Key Points to be Considered
-
Points to be Considered — From the above example and explanation, we understand the concept of “Self-Attention,” but If you see, we are doing it differently for each word/token separately. Surprisingly, we are just doing “vector multiplications“ and “dot products,” so we can do all these calculations parallelly (together) in one go. In addition to this, you see, there is no learning parameter because we are getting general embeddings. So, the solution of this problem we discuss below:
-
Parallel Operations — If you go through the process of self-attention again, you will see that there is nothing like the embedding of the first word depending on the second word’s embedding or vice versa. So, by taking advantage of it, we can easily create embeddings parallelly. It also increases the speed and saves us a lot of time but has one disadvantage, which is “Loose of a sequence of text.” This is further solved by “Positional encoding,” which we discuss in future blogs.
 Parallel Operations
Parallel Operations
-
No Learning Parameter — Right now, our self-attention model is giving us general embeddings that are not task-specific. So, we can expect good results for it; it will just provide general translations. To solve it, we add a learning parameter so that our model will learn along with it and provide better contextual embeddings (specific to the task we are performing).
-
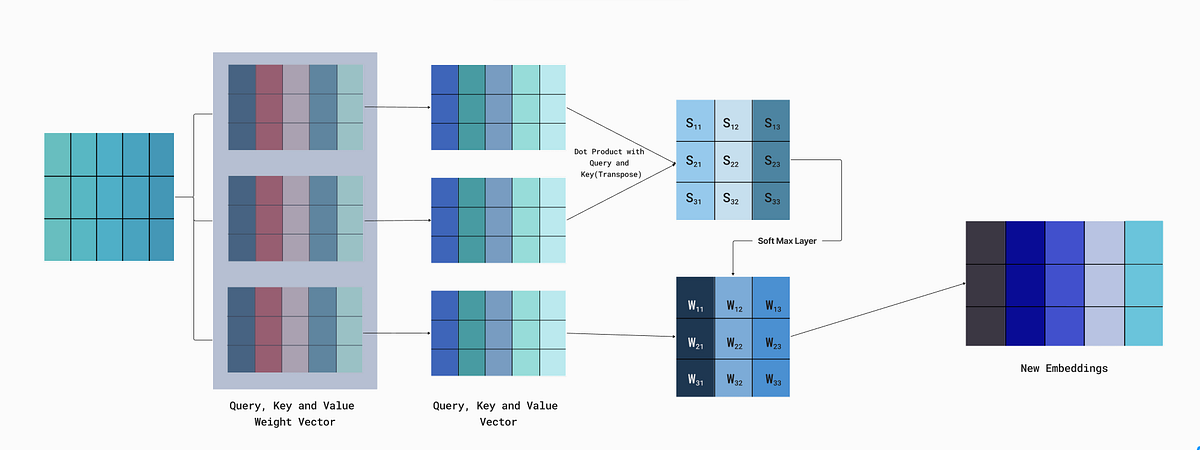
So, to do so, we convert our vectors into three different vectors:
- Query
- Key
- Value
Now, you may think about how we calculate them nowwww. We randomly assign these three matrices and then pass each embedding from it. We will get our “Query,” “Key,” and “And value.” These weights will updated with every training, and also these matrices are the same for all the word embedding for the entire batch.
-
Query — It represents the element of interest or the context that you want to obtain information about. It is usually derived from the current position in the input sequence or the output of the previous layer. In addition to this, it is used to determine the similarity or relevance between this context and other elements in the input sequence, specifically the key vectors.
-
Key — It is also like the query vector, is a projection of the input data, and is associated with each element in the input sequence. The key vectors are used to compute how relevant each element in the input sequence is to the query. This relevance is often calculated using a dot product or another similarity measure between the query and key vectors.
-
Value — The value vector is also a projection of the input data and is associated with each element in the input sequence, just like the key vector. The value vectors store the actual information that will be used to update the representation of the query. These values are weighted by the attention scores (computed from the query-key interaction) to determine how much each element contributes to the final output. The attention scores, computed based on the query and key, are used to weight the value vectors. Higher attention scores mean that the corresponding values are more important for the output.
2.3 Complete Process
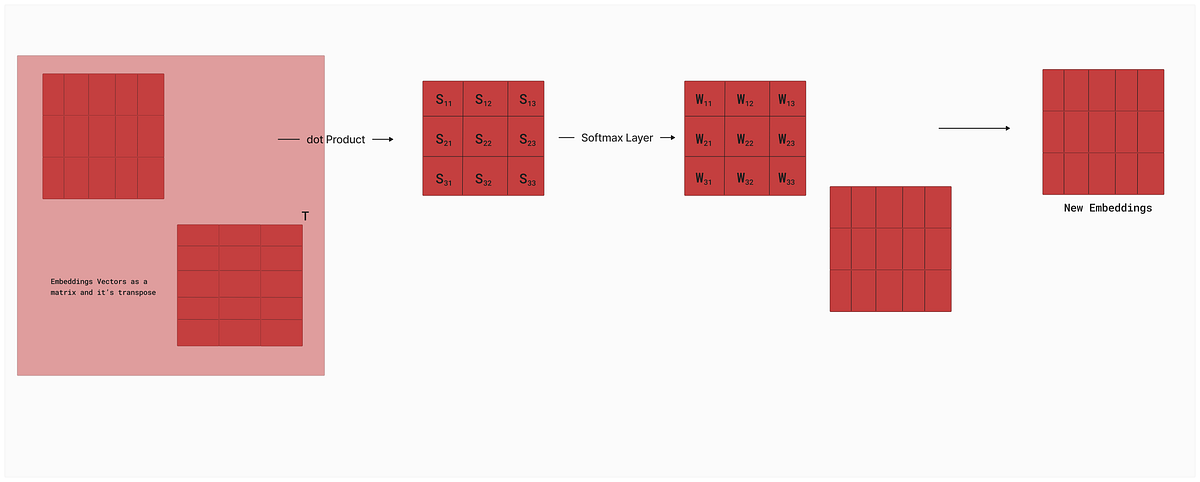
The query vector will dot the product with the key vector component of all the words, and then we pass it through the “SoftMax” layer and normalize it. After that, we do a dot product of these normalized vectors with value component and will get the new embeddings of the same size as our static embeddings.
 Complete Self-Attention
Complete Self-Attention
Now, we are at the end of our self-attention, and we have covered everything that is required to complete the process. Lastly, if we check the research paper in which they mention the self-attention concept, they also address the gradient vanishing problem in it. To handle this problem, we divide the dot product of the Query and Key vector with the dimensions of the key vector. Therefore, we get a mathematical formula that looks like this —
 Self-Attention Formula
Self-Attention Formula
Now, as we have done all the theoretical parts of self-attention. But now let’s do some coding around it —
Let’s change our sentence this time. So our new sentence is — “Hey welcome back”.
Step 1: Static Embeddings
static_embeddings = {
"Hey": [1, 0, 0],
"welcome": [0, 1, 0],
"back": [0, 0, 1]
}
Step 2: Creating Weighted Query, Key, and Value Matrices
import numpy as np
# Creating weight matrices with values between -1 and 1
# Weight matrix for Query
W_Q = np.array([[-0.5, 0.3, 0.8],
[0.1, -0.7, 0.9]])
# Weight matrix for Key
W_K = np.array([[0.6, -0.4, 0.2],
[-0.3, 0.7, -0.5]])
# Weight matrix for Value
W_V = np.array([[0.4, -0.6, 0.8],
[-0.9, 0.5, -0.2]])
# Printing the weight matrices
print("Weight Matrix for Query (W_Q):\n", W_Q)
print("Weight Matrix for Key (W_K):\n", W_K)
print("Weight Matrix for Value (W_V):\n", W_V)
Step 3: Computing Q, K, and V for each word
# Function to compute the Query, Key, or Value vector for a given word vector and weight matrix.
def compute_qkv(word_vector, W):
# Perform matrix multiplication of the word vector with the transpose of the weight matrix
return np.dot(word_vector, W.T)
# Compute Query vectors for all words by applying the W_Q weight matrix to the word vectors
Q = {word: compute_qkv(vec, W_Q) for word, vec in embeddings.items()}
# Compute Key vectors for all words by applying the W_K weight matrix to the word vectors
K = {word: compute_qkv(vec, W_K) for word, vec in embeddings.items()}
# Compute Value vectors for all words by applying the W_V weight matrix to the word vectors
V = {word: compute_qkv(vec, W_V) for word, vec in embeddings.items()}
# Display the resulting Query vectors for each word
print("Query vectors:")
for word, q in Q.items():
print(f"{word}: {q}")
Step 4: Computing Attention Scores
# Function to calculate the attention score between two vectors (query and key)
def attention_score(q, k):
# Compute dot product between query vector (q) and key vector (k)
# Divide by the square root of the dimension of the key vector (k.shape[0]) to scale
return np.dot(q, k) / np.sqrt(k.shape[0])
# Dictionary to store the attention scores for each word pair
attention_scores = {}
# Loop over every pair of words in the embeddings to calculate their attention scores
for word1 in embeddings:
attention_scores[word1] = {} # Initialize an empty dictionary for each word
for word2 in embeddings:
# Compute the attention score between word1's query vector and word2's key vector
attention_scores[word1][word2] = attention_score(Q[word1], K[word2])
# Display the attention scores between all pairs of words
print("\nAttention Scores:")
for word1, scores in attention_scores.items():
print(f"{word1}:")
for word2, score in scores.items():
# Print each attention score with 2 decimal places for readability
print(f" {word2}: {score:.2f}")
Step 5: Applying Softmax to Get Attention Weights
# Function to calculate softmax over a vector
# Softmax normalizes the attention scores into probabilities
def softmax(x):
# Subtracting the max value from x for numerical stability (avoids overflow issues with large exponentials)
exp_x = np.exp(x - np.max(x))
# Divide by the sum of all exponentials to get the softmax probabilities
return exp_x / exp_x.sum()
# Dictionary to store the attention weights for each word (softmax applied to attention scores)
attention_weights = {}
# Loop over each word and its corresponding attention scores
for word1, scores in attention_scores.items():
# Convert attention scores (which are stored as a dictionary) into a list and apply softmax
attention_weights[word1] = softmax(np.array(list(scores.values())))
# Display the attention weights (probabilities) for each word after softmax
print("\nAttention Weights:")
for word1, weights in attention_weights.items():
print(f"{word1}: {weights}")
Step 6: Computing the Final Output
# Dictionary to store the final outputs after applying the attention mechanism
outputs = {}
# Loop through each word in the embeddings
for word in embeddings:
# Compute the weighted sum of the value vectors (V) using the attention weights
# For each word, the sum is the weighted combination of the value vectors of other words
weighted_sum = sum(weight * V[other_word] # Multiply the attention weight by the corresponding value vector
for other_word, weight in zip(embeddings, attention_weights[word])) # Zip combines embeddings with attention weights for the word
# Store the result as the final output for the current word
outputs[word] = weighted_sum
# Print the final output vectors after the attention mechanism
print("\nFinal Outputs:")
for word, output in outputs.items():
print(f"{word}: {output}")
Step Parallelization:
# Create an array of embedding vectors for the words in the sequence "Hey" "welcome" "back"
input_sequence = np.array([embeddings["Hey"], embeddings["welcome"], embeddings["back"]])
# Compute the Query (Q), Key (K), and Value (V) matrices for the entire input sequence
# by multiplying the input sequence matrix with the respective weight matrices (W_Q, W_K, W_V)
Q_matrix = np.dot(input_sequence, W_Q.T) # Compute all Query vectors by multiplying with W_Q
K_matrix = np.dot(input_sequence, W_K.T) # Compute all Key vectors by multiplying with W_K
V_matrix = np.dot(input_sequence, W_V.T) # Compute all Value vectors by multiplying with W_V
# Print the Query, Key, and Value matrices for the input sequence
print("Query matrix (Q):")
print(Q_matrix)
print("\nKey matrix (K):")
print(K_matrix)
print("\nValue matrix (V):")
print(V_matrix)
# Calculate attention scores for all pairs simultaneously
scores = np.dot(Q_matrix, K_matrix.T) / np.sqrt(K_matrix.shape[1])
3. Conclusion
1. Understanding Contextual Embeddings
The self-attention mechanism allows for calculating contextual embeddings using Query, Key, and Value matrices, enabling models to dynamically weigh the importance of different words in a sentence based on their relevance.
2. Importance of Scaling and Softmax
By scaling the dot product of the Query and Key matrices and applying the Softmax function, we ensure that the resulting attention scores are normalized, facilitating the model’s ability to focus on significant contextual relationships within the text.
3. Capturing Long-Range Dependencies
Self-attention is integral to modern NLP models, as it effectively captures long-range dependencies in text, enhancing the model’s overall comprehension and performance in various language tasks.
Thanks for reading this article 🤩
Let’s stay in touch on LinkedIn, GitHub, and Instagram — ❤️to keep the conversation going!
See you again next time, have a great day ahead
I’d love to hear your thoughts, answer questions, and collaborate on exciting projects in AI and machine learning! Thank you for reading 🤗
Comments